I initially created this site with the intention of it being a place to simply host my portfolio works, many of which I couldn't host on a public GitHub repository as they were class projects. However, I'd wanted to have a place to store and share various personal interests, and that added requirements to make the website easily scalable (especially with adding new pages to the navigation bar).
This led to me developing a simple SQLite database to store page information for auto-generating the navbar, a CRUD commandline interface in Rust to update that database, PHP to generate HTML using the info in the database and other repeat structures, and then all the CSS, JS, and HTML content which the site runs on. In order to have complete control over the appearance and content of the site, I chose to not use any external JavaScript packages/frameworks nor CSS frameworks (for better and worse). As such, everything you see is my own creation or adaptation from examples which I like on the web (especially MDN).
Workflow and Utilities
The workflow I chose to use was to first create a page in PHP which includes utils that programmatically generate the navigation bar based on my database's content, add the file to the database using my CLI, then run a script to generate HTML from every PHP file so each page has the updated navigation bar, finally pushing the files to my server using a simple shell script after building with Vite.
Example Workflow
One of the standout points of this may be the way in which I generate the HTML from the PHP prior to pushing the files to the server for hosting. As I found out after the fact, this follows the principals of Static Site Generation, but with my PHP and scripts taking place of common generators. I made the decision to develop my site in this way due to the small size of the server I rent from. As it is relatively cheap, the processor which I access is virtualized and shared with multiple other servers. This means that any computationally expensive operations are likely to get bottlenecked within the CPU since it is not dedicated to my server alone. As such, I run all of the PHP files on my local machine and then use my server to host just the output HTML files in order to save the computation from generating the file upon request (which would not be much, thereby making this optimization quite nitpicky, but whatever).
Note that this only is possible because the contents of each page stay constant, only updating when I need them to. In a larger web application with users, the database may be updated with user input at any point and thereby may be unable to serve solely static HTML pages. Of course, if I ever add any user-based programs, as I rent the server myself and am not relying on CDNs to host this site, I can always just add dynamically generated pages which Apache will be able to serve.
The main choke point for this workflow was the navigation bar due to how every single page needs to be updated with the correct navbar any time a new page gets added, removed, or is modified. My approach to this was to represent a hierarchy of pages through defining a document for a page, or a category for a grouping of pages (potentially with a linked index page) within a simple database. Nested categories are also possible, but with the limitation that each category is allowed up to one parent category, however a category may contain none or many documents.
Entity Relationship Diagram (ERD) Depicting The Navigation Hierarchy
Having a database storing the hierarchy in this way allows for documents to be held under multiple categories without issue, and for nesting of categories in a somewhat sensible way. In order to generate the navigation bar in HTML, I created a PHP utility function which recursively builds a tree of category and document nodes using the items stored in the database. This tree is then traversed in preorder fashion to output the structure of the navigation bar properly.
navbar.php
<?phprequire_once__DIR__ . "/database_connection.php";
require_once__DIR__ . "/tree.php";
/**
* A simple representation of an anchor within the navbar
*/classNavElemData{
public string $href;
public bool $isActive;
public bool $isCategory;
private string $title;
publicfunction__construct(string $title, string $href, bool $isCategory = true){
$this->title = $title;
$this->href = $href;
$this->isCategory = $isCategory;
$this->isActive = false;
}
/**
* Default toString function which doesn't add a class for the depth of the item
*/publicfunction__toString(){
// construct a node with classes depending on if its a category or document and active status
$category = $this->isCategory ? "nav-category" : "nav-document";
$active = $this->isActive ? "active " : "";
$classes = "class=\"$active$category\"";
$button = "";
if ($this->isCategory) {
$button = "<button class=\"button nav-category-button header-dropdown-toggle $active\" aria-expanded=\"false\">$this->title</button>\n";
}
return"$button<a $classes href=\"$this->href\">$this->title</a>";
}
/**
* Essentially the same as the standard toString function, but will add
* a header-dropdown-toggle button if there is a list to dropdown
*
* @param bool $hasChildren whether the node has child nodes or not
*/publicfunctiongetHTML($hasChildren){
// construct a node with classes depending on if its a category or document and active status
$category = $this->isCategory ? "nav-category" : "nav-document";
$active = $this->isActive ? "active " : "";
$classes = "class=\"$active$category\"";
$button = "";
if ($this->isCategory && $hasChildren) {
$button = "\n<button class=\"button nav-category-button header-dropdown-toggle $active\" aria-expanded=\"false\">$this->title</button>\n";
}
return"$button<a $classes href=\"$this->href\">$this->title</a>";
}
}
/**
* Recursively creates a hierarchy of lists and anchors on the navbar
* @param Node $node the tree to build up
* @param PDOStatement $statement the statement to execute recursively
* @param int $activeItemID the ID of the item containing the active file (or -1 if none)
* @param bool $setActiveOnDocument true if the active item is a document, or false if it is a category
* @return void Node[]
*/functionrecursiveBuildTree(Node $node, PDOStatement $statement, int $activeItemID, bool $setActiveOnDocument){
static $highlitActiveCategory = false;
global $db;
if ($statement->execute() === false) {
die("Failed to execute the query: $statement->queryString");
}
$categories = $statement->fetchAll();
foreach ($categories as $category) {
// set up a node for this category in the nav
$categoryID = $category["cat_id"];
$name = match ($category["cat_name"]) {
null => "UNTITLED",
default => $category["cat_name"],
};
$href = $category["cat_index_path"];
$catNode = new Node(new NavElemData($name, $href));
$node->addChild($catNode);
// conditional to add active class to the hierarchy of tags above this depthif (!$setActiveOnDocument && $categoryID === $activeItemID) {
// unset the href for the category and set it as active as its index is active
$catNode->data->href = "#";
$catNode->data->isActive = true;
// highlight the first (earliest encountered) category containing this document// as well as the categories containing that category, ignore any other onesif (!$highlitActiveCategory) {
// traverse up the ancestor categories of this document and highlight them
$parent = $catNode->parent;
while ($parent != null) {
if ($parent->data != null) {
$parent->data->isActive = true;
}
$parent = $parent->parent;
}
$highlitActiveCategory = true;
}
}
// recur on the categories which are subcategories of the current category
$statement = $db->prepare(
"SELECT * FROM category
WHERE category.parent_id = :cat_id
ORDER BY category.cat_position, category.cat_name ASC;"
);
$statement->bindParam("cat_id", $categoryID);
recursiveBuildTree($catNode, $statement, $activeItemID, $setActiveOnDocument);
// add documents which are present within this category now that all subcategories are added
$statement = $db->prepare(
"SELECT d.doc_id, d.doc_title, d.doc_date, d.doc_path FROM document d
INNER JOIN categorydocument ON categorydocument.doc_id = d.doc_id
WHERE categorydocument.cat_id = :cat_id
ORDER BY categorydocument.catdoc_position, d.doc_title ASC;"
);
$statement->bindParam("cat_id", $categoryID);
if ($statement->execute() === false) {
die("Failed to execute the query: $statement->queryString");
}
$documents = $statement->fetchAll();
foreach ($documents as $document) {
// set up a node for this document in the nav
$documentID = $document["doc_id"];
$title = match ($document["doc_title"]) {
null => "UNTITLED",
default => $document["doc_title"],
};
$href = $document["doc_path"];
$docNode = new Node(new NavElemData($title, $href, false));
$catNode->addChild($docNode);
// conditional to add active class to the hierarchy of tags above this depthif ($setActiveOnDocument && $documentID === $activeItemID) {
// unset the href for the current file and set it as active
$docNode->data->href = "";
$docNode->data->isActive = true;
// highlight the first (earliest encountered) category containing this document// as well as the categories containing that category, ignore any other onesif (!$highlitActiveCategory) {
// traverse up the ancestor categories of this document and highlight them
$parent = $docNode->parent;
while ($parent != null) {
if ($parent->data != null) {
$parent->data->isActive = true;
}
$parent = $parent->parent;
}
$highlitActiveCategory = true;
}
}
}
}
}
// see https://www.php.net/manual/en/class.sqlite3stmt.php for stuff about binding params in queries/**
* Constructs the navigation bar, adding the active class to the anchors
* which include the activeFile.
* @param string $activeFile the filename or filepath to set active
* @return void
*/functionnavConstructor(string $activeFile){
global $db;
$tree = new Tree();
// first get the ID of the active document upfront so as to not process this request many times
$statement = $db->prepare(
"SELECT document.doc_id FROM document
WHERE document.doc_path = :active_file_path;"
);
$statement->bindParam("active_file_path", $activeFile);
if ($statement->execute() === false) {
die("Failed to execute the query: $statement->queryString");
}
$result = $statement->fetch();
$activeItemID = -1;
$setActiveOnDocument = false;
if (is_array($result)) {
$activeItemID = $result["doc_id"];
$setActiveOnDocument = true;
} else {
// no document with that path specified, so now search the index paths of categories for it
$statement = $db->prepare(
"SELECT category.cat_id FROM category
WHERE category.cat_index_path = :active_file_path;"
);
$statement->bindParam("active_file_path", $activeFile);
if ($statement->execute() === false) {
die("Failed to execute the query: $statement->queryString");
}
$result = $statement->fetch();
if (is_array($result)) {
$activeItemID = $result["cat_id"];
$setActiveOnDocument = false;
}
}
// begin by selecting the list of root categories (ones with no parent)
$statement = $db->prepare(
"SELECT * FROM category
WHERE category.parent_id IS NULL
ORDER BY category.cat_position, category.cat_name ASC;"
);
recursiveBuildTree($tree->root(), $statement, $activeItemID, $setActiveOnDocument);
// tree is now built
$unclosed = [];
$prevDepth = -1;
$generateNavHTML = function(Node $node)use(&$unclosed, &$prevDepth){
// ERROR CHECKING// ensure we are not stepping more than 1 node deeper than prevDepth, upwards is okayif ($node->depth - abs($prevDepth) > 1) {
$title = $node->data->title;
$parTitle = $node->parent->data->title ?? "";
$parDepth = $node->parent->depth ?? "";
die("Encountered a disjointed node titled: $title jumping from prevDepth: $prevDepth to depth: $node->depth
The parent of this node is the node titled: $parTitle with depth: $parDepth");
}
// ROOT CASEif ($node->parent == null) {
// open up the initial ulecho"<ul id=\"nav-main-list\">\n";
return;
}
// NON-ROOT CASE// close the previous depth up to where it should be// when $prevDepth == $node->depth no lists need to be closedfor ($i = $node->depth; $i < $prevDepth; $i++) {
$toClose = array_pop($unclosed);
// unnecessary check as nothing gets pushed onto unclosed if it has no children, but w/eif ($toClose->numChildren > 0) {
echo"</ul>\n";
}
if ($toClose->depth == 1) {
echo"</div>\n";
}
echo"</li>\n";
}
// opens the li with classes specifying its dropdown status and depth// if it has children, opening a new ul if so, otherwise simply// adding the anchor tag for the node and closing the li afterif ($node->numChildren > 0) {
$liClasses = match (true) {
$node->depth < 0 => "",
$node->depth == 1 => " class=\"nav-dropdown-base\"",
// default => " class=\"nav-dropdown-$node->depth\"",default => " class=\"nav-dropdown-subcategory\"",
};
// when on the base dropdowns which display in the nav,// a div should always be placed which aligns the dropdown// bubble properly when expanding
$nodeHTML = $node->data->getHTML(true);
echo"<li$liClasses>$nodeHTML";
if ($node->depth == 1) {
echo"<div class=\"nav-dropdown-container\">";
}
$ulClasses = match (true) {
$node->depth < 0 => "",
$node->depth == 1 => " class=\"nav-dropdown-column header-dropdown-list\"",
default => " class=\"nav-subcategory-list header-dropdown-list\"",
};
echo"\n<ul$ulClasses>\n";
array_push($unclosed, $node);
} else {
$nodeHTML = $node->data->getHTML(false);
echo"<li>$nodeHTML";
// just close this li immediatelyecho"</li>\n";
}
$prevDepth = $node->depth;
};
// construct the majority of the HTML for the navbar
$tree->preorder($generateNavHTML);
// close anything left in unclosedfor ($i = count($unclosed); $i > 0; $i--) {
$toClose = array_pop($unclosed);
// unnecessary check as nothing gets pushed onto unclosed if it has no children, but w/eif ($toClose->numChildren > 0) {
echo"</ul>\n";
}
if ($toClose->depth == 1) {
echo"</div>\n";
}
echo"</li>\n";
}
// close the root ulecho"</ul>\n";
}
With the navigation bar being properly generatable, all that was left was adding rows to the tables in the database. While it would be simple to write out the SQL myself for how small of a project this was, I decided to create a command line interface (CLI) in Rust to gain experience with the language and for ease with updating the database. I plan to continue working on and improving the CLI as I would like to make it extensible for the future where my habits when updating the database may change. As a utility, the CLI gives a nicer way to visualize the database's tables on top of streamlining updating the database.
Setting Up For Local Development
This section was added
Building with Vite and Pushing with rsync
Recently I updated my local development cycle to include Node.JS and Vite for building required files, preparing them for pushing to the server. This allows for multiple improvements, namely minification of the HTML, CSS, and JS files of the site; hashing of the filenames for assets so as to bust caching by browsers when changes are made, allowing visitors to stay up to date with the site; and bundling of common JS modules on the site, reducing necessary file requests.
As my website is not as simple as the single-page applications which Vite is more commonly used for, I have a more unique setup for my Vite configuration which will search through all of my .php files using a glob and create an entry point for Rollup (the bundler) from each of their associated .html files. I also ran into some issues with Rollup combining some of my .css files when I didn't intend for them to, so I included those as entry points as well, which seemed to fix the issue even though it may be a bit hacky. On top of this, I wanted to have my .html files minified, and so made use of vite-plugin-html-minifier to reduce the size of the output .html files. Here is my config file for reference:
vite.config.js
import { defineConfig } from"vite";
import htmlMinifier from"vite-plugin-html-minifier";
import { globSync } from"glob";
import path from"path";
import checker from"vite-plugin-checker";
functiongetAllEntryFiles() {
const htmlEntries = Object.fromEntries(
globSync("php/**/*.php", {
ignore: ["php/utils/**"],
}).map((file) => {
// remove the preceding php directory and the ending extensionconst base = path.relative(
"php",
file.slice(0, file.length - path.extname(file).length)
);
return [
base,
// second element is the mapped to value, which is the associated .html file
path.join(__dirname, base + ".html"),
];
})
);
// as I want to ensure some modularity between the sub-sites,// any CSS files beginning with `main` are treated as individual entry pointsconst mainCssEntries = Object.fromEntries(
globSync("**/main*.css", {
ignore: ["php/**", "node_modules/**", "ignore/**", "code-files/**"],
}).map((file) => [
file.slice(0, file.length - path.extname(file).length),
path.join(__dirname, file),
])
);
return { ...htmlEntries, ...mainCssEntries };
}
exportdefault defineConfig({
root: ".",
build: {
outDir: "dist",
emptyOutDir: true,
rollupOptions: {
input: getAllEntryFiles(),
output: {
assetFileNames: "assets/[name]-[hash][extname]",
chunkFileNames: "[name]-[hash].js",
entryFileNames: "[name]-[hash].js",
},
},
minify: "terser",
terserOptions: {
compress: {
drop_console: true,
},
},
},
plugins: [
checker({
typescript: true,
}),
htmlMinifier({
minify: true,
}),
],
resolve: {
alias: {
lib: "/graphics/lib",
},
},
});
By having the website be built by Vite, the files would be output to the /dist directory, which would subsequently add a new prefix to the requires links for each anchor tag were I just uploading my files through Git Remotes as I had before (e.g. the file is at /dist/example.html instead of the original href of /example.html). Clearly, this would not work to maintain the file structure required for the server to serve the minified files were I to push changes to the server using Git Remotes (at least not easily). This led to me instead using the rsync shell function to push my changes as it handles incremental copying well. To make this even easier, I wrote a very simple bash script to handle my uploads:
upload.sh
#!/bin/bash
# This script syncs all content in dist and copies other important directories# to my website for proper hosting
dest="USER@WEBSITE:/var/www/DOMAIN-NAME/"# Run the find command to search just the current directory (-maxdepth 1)# for directories (-type d) with the name "dist" that are not empty,# then pipe that name to a shell which runs printf with the directory name# as its argument, appending a trailing / as find does not keep trailing slashes# The {} at the end specifies that the filename should be passed as an argument# to the sh command, and the \; escapes the ; character to tell find to stop# appending content to the parameters of the command passed to -exec
dir=$(find . -maxdepth 1 -type d -name "dist" -not -empty -exec sh -c 'printf "%s/" "$0"' {} \;)
# ensure there is a valid dist directoryif [[ -z $dir ]]; thenecho"dist is empty or not found"else# copy all of the content of the dist directory up to the destination
rsync -av $dir$dest# also copy up the contents of ./games/lyric-guessr/scripts as# vite does not copy non-module js to dist# the -R flag here preserves relative file structure
rsync -avR "./games/lyric-guessr/scripts"$dest# do the same thing for the data directory as vite only copies# css, html, and js to dist unless in the public directory
rsync -avR "./data"$dest# and the dhcp_reqs directory just because
rsync -avR "./portfolio/dhcp_reqs"$destfi
One of the other unintended advantages of this method of pushing changes is that I can now store in my local Git repository for the website any files which are important to my local development. Previously, I would have a separate remote specified and would need to go through a lot of trouble to commit my local development files for backup to GitHub and then remove those commits for the sake of pushing to the site. However, I am now able to have the Git repository act solely as a backup for my local development, which is much neater I feel. This also decreases some bloat on the server as it has no need to store commit histories or anything of that sort, instead just getting only the required files for the site and nothing more.
Keep in mind that all of this is running with Node.js, and is rather easily installable through npm. For my case, I find that development is a little bit easier using Linux, and so have installed all of this on WSL, with my VSCode "remotely connected" to WSL for development. Here is my package.json for reference as well:
Note that in my defined scripts I refer to the local program ./runphp, this is just a simple runner program I wrote in rust that converts all php files stored in my /php/ directory into an html file with the same relative path but out of root. The -f flag ignores any of my rudimentary "dirty file" optimizations and forces all files to update, which is important when I update a file that some page includes in its contents but not the page itself as the php file itself wasn't modified yet its content was.
Creating the Server
Steps for Setup
The steps I took for creating the site are as follows:
I chose the platform which I wanted to host my server on, deciding on DigitalOcean for ease of setup, familiarity as I had used it as a host in a previous class, and recommendation from a professor who hosts their own site similarly. Many other options exist though (e.g. AWS, Azure, Vultr, etc.) and anyone using this as a guide should look into the many options before settling.
I also purchased the domain name I use from GoDaddy as it was the first domain registrar I thought of (it has a funny name). Once I acquired the domain I updated my domain's delegation and then added a DNS A record to my DigitalOcean control panel to point to my server.
After choosing the server size I wanted and preparing my Droplet to run Ubuntu, I followed this guide by Jamon Camisso and Anish Singh Walia to get my user set up, enable a simple firewall, and add SSH keys for remote access from my PC.
As my server is meant for hosting a standard HTTP/HTTPS website, I needed some program to listen for traffic and requests and serve the proper webpages, and the web server I chose was Apache. This was purely out of experience with it from time in my classroom, but there are alternativs like Nginx and Lighttpd which are also feasible. In order to set up Apache I followed this guide by Erin Glass and Jeanelle Horcasitas.
HTTPS traffic requires that there is some encryption done by the server and client when transferring data, and in order to do that encryption a site needs some Secure Socket Layer (SSL) certificate to identify itself. Typically, an SSL certificate costs money, but many sites now are able to use LetsEncrypt to obtain and renew an SSL certificate programmatically for free. As such, I followed this guide by Jeanelle Horcasitas, Erika Heidi, and Anish Singh Walia to add LetsEncrypt onto my server.
Given that I was following the workflow of add changes on my machine -> commit with git -> push changes remotely I needed to add a way to have the repository on the server copy over the files and changes to the /var/www/domain-name directory which is typically not able to have repositories made directly within the file, at least for a simple user. Git Hooks are perfect for this, specifically the post-receive hook which runs following receiving a push to the repository. Within my repository that I created in /var/repo/domain-name.git's hooks directory, I added the following post-receive hook script which places the pushed changes into the TARGET directory:
post-receive
#!/bin/sh
# the working tree of the site to deploy changes to
TARGET="/var/www/DOMAIN-NAME"# the location of our .git directory
GIT_DIR="/var/repo/DOMAIN-NAME.git"# running branch
BRANCH="main"
git --work-tree="${TARGET}" --git-dir="${GIT_DIR}" checkout -f ${BRANCH}
Once that was set up, I could use git push as normal to push any changes to the server from my home computer using my standard user, with those changes being put into the /var/www/domain-name directory for proper serving by Apache.
I (as of ) no longer use Git Remotes to push my changes to the server, and instead use the methodology described in the local development setup section. As such, this is not necessary for me, but is still useful information.
Challenges
Background
Many of the challenges that I encountered with this project come as a consequence of the expense of renting the server space. Renting a server is not necessarily cheap, and upgrades to hardware will inevitably lead to an increase in the cost of renting it. For example, I initially was running my server on the cheapest DigitalOcean plan ($4/month), but this only gave me access to 10GB of storage for everything, including system utils. Very quickly this space reached capacity without much of my own content stored on the server, leading me to upgrade to a plan with 35GB of storage (along with improvements to CPU, memory, and transfer limit), which doubled my monthly cost ($8/month).
While this cost of running isn't anything exorbitant, ignoring the constraints of this server would result in a need to undo work or upgrade for more money. As such, any programs running on the server I attempt to make have as little overhead as possible, and I must be attentive to the requests made to the server early on.
Efficient Server for LyricGuessr
LyricGuessr, the lyric guessing game I made, runs using the Spotify and Musixmatch APIs which both require some private key hidden from the client when making requests. As JavaScript makes all variables public to the user in the developer console, anyone who went looking would be able to find and use my private API key. While this is really not that much of an issue given the keys are free and thereby so restrictive they're essentially useless to steal, following good practice is important for learning. Due to this, I set up server program to handle requests for LyricGuessr. You can learn more in depth about this on its portfolio page.
This program would be theoretically running at all times, which may become an issue in the future as the CPU the server runs on is virtualized and shared amongst other servers on the same machine. Were more programs to become required for functionality in other parts of the server, inefficiencies on the program could slow down or prevent some tasks from running as the CPU runs more and more. As such, a decision needed to be made about what language the program would be written in and how much overhead is tolerable for such a small server.
For me, there were essentially three options available for the language to use: JavaScript, Python, and Rust. JavaScript using Node.JS has a lot of examples on the web, with it being Spotify's choice when giving examples of the Authorization Code Flow which LyricGuessr uses. Python has seen growing use in backend programming and also has many well-documented frameworks to build off of. Rust is very new to the space of backend programming and has very little documentation for backend development outside of a few packages. However, both JavaScript and Python are interpreted languages, thereby requiring some overhead in the form of the interpreter process which converts the code text at runtime into runnable code. This overhead is very little once optimization is done, however it still exists and would likely double the actual CPU use of the server itself (though that is very small). Rust, however, is a compiled language which guarantees that the program has no such overhead. The safeties guaranteed by the type-checker may allow for some optimizations of efficiency in running as well, potentially garnering even more efficiency gains over JavaScript and Python. This led Rust to being the obvious choice for the LyricGuessr server, and likely any similar servers I would write in the future.
I bring this up to illustrate that when working on a constrained system, understanding the tools which you work with is extremely important. While the benefits of those optimizations aren't immediately evident, there is a good likelihood that in the future I will thank myself for not needing to revisit, reunderstand, and potentially rewrite these subsystems.
Unexpected Traffic
One of the biggest issues I encountered is one with the server seemingly being botted by some collection of foreign servers repeatedly requesting TCP connections. Given that my site has not been shared with anyone and there is no content which is being requested with these connections, there is no reason for my server to receive any TCP requests, especially not in the volume that it is receiving them. This is somewhat of an issue due to the way in which DigitalOcean handles transfer out from the server, with an allowance of 1TB of outgoing transfer per month with the plan I currently use. Any transfer over this limit results in some additional charges per GB over. As such, it would be worthwhile to monitor and block these requests somehow. Using TCPDump to monitor traffic, I am able to see which IPs and providers the requests are being made by.
Output of Very Briefly Running `sudo tcpdump -l -n -i eth0 "dst port 443 and inbound and not src <SERVER-IP>" -w incoming_traffic.pcap`
tcpdump: listening on eth0, link-type EN10MB (Ethernet), snapshot length 262144 bytes
23:07:40.886147 IP (tos 0x0, ttl 221, id 28915, offset 0, flags [DF], proto TCP (6), length 60)
192.141.233.69.21616 > MY-SITE.https: Flags [S], cksum 0x4ce1 (correct),
seq 148437502, win 8192, options [mss 8960,sackOK,TS val 1102093998 ecr 0,nop,wscale 2], length 0
23:07:40.902448 IP (tos 0x0, ttl 220, id 49560, offset 0, flags [DF], proto TCP (6), length 60)
131-108-189-56.totalwebinternet.com.br.45334 > MY-SITE.https: Flags [S], cksum 0x6973 (correct),
seq 1671885386, win 0, options [mss 1492,sackOK,TS val 1258188642 ecr 0,nop,wscale 8], length 0
23:07:41.106537 IP (tos 0x0, ttl 220, id 49560, offset 0, flags [DF], proto TCP (6), length 60)
131-108-189-51.totalwebinternet.com.br.19729 > MY-SITE.https: Flags [S], cksum 0x1dfc (correct),
seq 4087615950, win 0, options [mss 1492,sackOK,TS val 1258188642 ecr 0,nop,wscale 8], length 0
23:07:41.271536 IP (tos 0x0, ttl 220, id 49560, offset 0, flags [DF], proto TCP (6), length 60)
170-79-33-30.wantel.net.br.18319 > MY-SITE.https: Flags [S], cksum 0xd772 (correct),
seq 3983137094, win 0, options [mss 1492,sackOK,TS val 1258188642 ecr 0,nop,wscale 8], length 0
23:07:41.502155 IP (tos 0x0, ttl 221, id 28915, offset 0, flags [DF], proto TCP (6), length 60)
191.6.251.81.42053 > MY-SITE.https: Flags [S], cksum 0x827f (correct),
seq 1210524855, win 8192, options [mss 8960,sackOK,TS val 1102093998 ecr 0,nop,wscale 2], length 0
Many of the requests are coming from the same few network hosts in Brazil with some rotating IPs, indicating that the server is being botted automatically for whatever reason. In order to block these IPs, I wrote a few bash commands to extract them from the TCPDump and block them using a rule on Uncomplicated FireWall (UFW).
In order to get a list of the servers which are making requests to the server, I run
sudo tcpdump -l -n -i eth0 "dst port 443 and inbound and not src <SERVER-IP>" -w incoming_traffic.pcap
allowing TCPDump to collect the incoming packets on port 443 (HTTPS) that don't originate from the server itself, that use the eth0 interface (-i eth0), and without converting IPs to hostnames (-n) all written into the incoming_traffic.pcap file (-w). This allows for packets to be captured in the background until the command is stopped with CTRL+C.
After enough time, that command is stopped and the packets captured are interpreted and the IPs are extracted from each packet using
Which uses grep to run a Perl regular expression (-P) to output just the matched IPs (-o). These retrieved IPs are then filtered to have just one copy of each with uniq and sorted, outputting to ips_full.txt. The Regex works by looking for the a match of either ip or IP, skips any number of spaces with \s+ and then grabs any number of characters until another space is encountered with \K[^ ]+.
Then, as there are many IPs that are subnets of the same network, some are able to be combined into a CIDR range which reduces the number of rules which would need to be made as the range covers many IPs at once. To create CIDR ranges from the list of IPs either
are run depending on if the range should be based on the first 24 bits or first 16 bits of the IP. These once again use grep and a Regex, this time to extract a certain number of octets in decimal followed by a period or whitespace as these are IPv4 addresses in dotted decimal notation as in ###.###.###.### and only the first few numbers are desired for the CIDR range. After the desired number of octets are extracted with grep, sed is used to append to the end of the now shortened IP address the desired CIDR range ending (.0/24 for 24 bit or .0.0/16 for 16 bit). Duplicates are once again removed and the CIDR ranges are sorted.
Finally, a simple shell script which iterates over each IP/CIDR in an input file and adds a blocking rule to UFW for one is run. After each is run, UFW is restarted and the rules are applied.
block_ips.sh
#!/bin/bash
# Read each line from the passed filewhileread -r ip; do# Skip empty lines (-z "$ip") and comments (start with #)if [[ -z "$ip" || "$ip" == \#* ]]; thencontinuefiecho"Blocking IP/CIDR: $ip"
sudo ufw insert 1 deny in from "$ip"doneecho"Reloading UFW"# Apply changes
sudo ufw reload
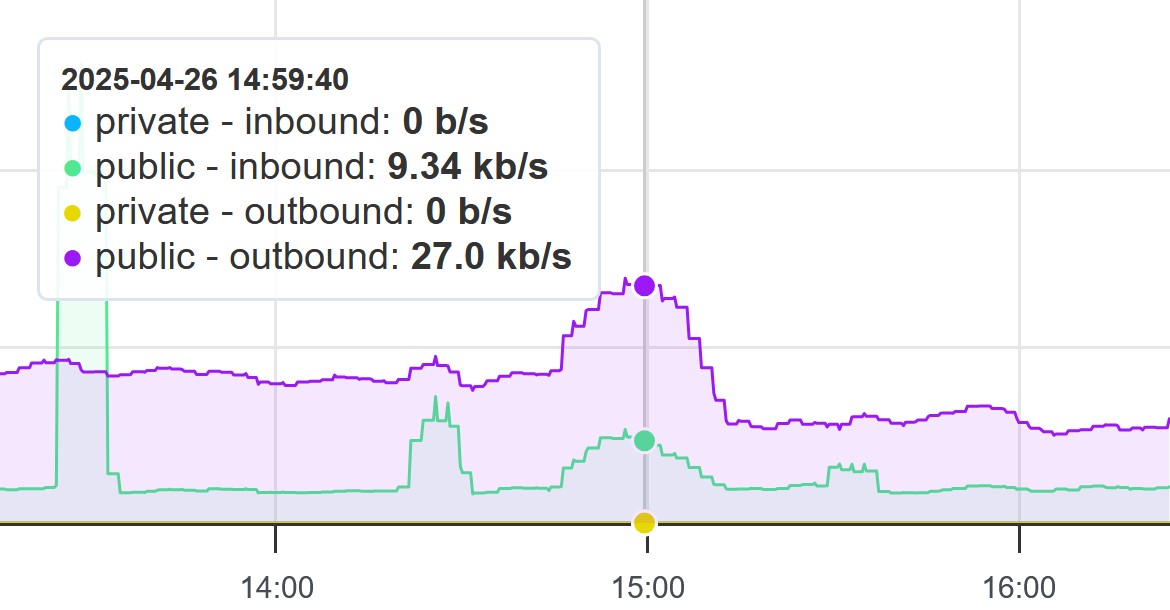
While not necessarily the optimal solution as it results in a potentially large number of rules in UFW, there is a clear effect on the number of outbound packets being sent by the server in response. In the graph below, the bump centered at 15:00 occurred following a removal of all prior UFW blocking rules, and the decrease in outbound traffic occurred after going through this process and blocking the offending IPs.
A Graph of Traffic Before and After Blocking With UFW
As you can see, the amount of outbound traffic was halved after the UFW rules were reinstated, and as new IPs were blocked it also decreased in comparison to the prior set of blocking rules.
I bring up this issue because not only is it a potential solution, though there are likely much better ones out there, but it is also illustrative of my ability to identify problems and work toward a solution with the various tools at my disposal. Shell scripting is extremely powerful when knowing how to use and chain commands, and while I am not anywhere near a master with Bash, I am able to understand and improve with those tools as needed.