This is a collection of notes which I wrote to occasionally from to , which coincides with my graduation from PVCC and my first semester at JMU studying computer science. The notes were initially written on a google doc I shared with my friends and initially served to attempt to improve all of our understanding of programming for the sake of making games in Unity. This page of notes serves mostly as an archive for those older notes as well as practice in taking the graphics/figures from that document and converting them to HTML and CSS in the site's style.
Given that these notes coincide with such an early time in my educational career, I do not consider them to be very good. For the most part, I archive them for posterity's sake (even if not very educational/useful), as practice for developing notes (as stated before), and because I do feel that there is an infinitesimal chance someone may discover and glean something from them. Often as we get to know more about a subject it becomes difficult to remember exactly where we struggled prior, or the things which we found interesting or important. This acts as a time capsule for what I put attention to at a time when I knew essentially nothing, and serves as a reference for myself to try and be understandable in the future as I contribute more information to this site.
When creating a program of any form, it is important to understand the variety of tools that are available for program creation. This goes for coding in Unity as well, and so this section is meant to detail aspects of programming that I find important to understand in order to code efficiently.
Functions vs Methods
It is extremely important to establish exactly what a function in programming is in general. A function is different from a method in that a method is tied to an object and, unless static, exists only with that object. For an example of what I mean, take the following code that depicts a function, then that which depicts a method:
As you can see, the function exists independent of a class and doesn't necessarily need an object to be made in order to be called. For an even clearer example, take this main method that calls both the function and method:
publicstaticvoidmain(String args[]){
exampleFunction();
exampleClass classObject = new exampleClass();
classObject.exampleMethod();
}
In this example, you can see the way in which a method requires a root object to work, but a function does not. Also, keep in mind that the above code was done using Java just because I feel it is most obvious in Java.
In short, remember that methods are functions, but require an object in order to exist and will typically alter some aspect of an object or use the object for some form of action. These differences become important when attempting to learn the difference between programming paradigms.
Expressions vs Statements
While this isn't necessarily an important thing to know and I may actually use the wrong term occasionally throughout this, I use them correctly most of the time, just so you know why this part is useful to know… also it's jargon so that's always important.
In programming, pretty much every complete action is a statement. Incrementing a value, looping through a list, checking if something fits a condition, all of these are statements. Essentially, a statement does something and is extremely general because of such.
An expression, on the other hand, is a more specialized statement that is defined as just something that evaluates and returns a value. All expressions are just a subset of statements and involve things like if statements, which return boolean values; functions, as they will always return something (null if void); and even simple math, which returns a value depending on an input. Each of these is an example of an expression as they evaluate to a value rather than simply updating or mutating a program's state. An expression can contain statements, as in a function, but they are defined as just a statement that returns a value. As such, understand that when I use the term "Expression" I mean it in this sense, but when using the term "Statement" it could be an expression or just a simple statement. Confusing, I know, but it's less confusing than just using "Statement" everywhere.
Compilation Deep Basics
This section will serve as a completely optional baseline to understanding the ways in which compilation works in general. Some ideas may be referenced in later sections, but you will likely not need this much information unless you are curious about deeper ideas. Also, keep in mind this information is based on the C/C++ compilation steps, which apply to (I assume) every language, but some specifics may change, such as preprocessor directives. This section also does not apply to Interpreters, but those are more easy to understand.
In code compilation, there are 3 steps that the code goes through in order to produce an executable file, with these steps being considered the Front End, Middle End, and Back End, in order. The act of Compilation overall is just parsing and converting the code into assembly instructions stored in a file ending in .obj. These .obj files are then linked together by something called the Linker, which is what produces the final executable file.
The Front End of Compilation (Preprocessing, Lexing, Parsing)
There are typically two steps that occur during the Front End in order to change the human-written code into machine-readable bytecode. In C++, the first step is that the compiler does a starting pass over the code using what is known as a preprocessor. This pass will search for any preprocessor directives that have been defined and mutate the code in some way by computing the directive in the manner that has been defined by the language. In C++ all preprocessor directives are lines that start with the hashtag character (#) and the most clear one to illustrate how this works is the #include directive, an example of which is shown here:
// this is the very top of the file#include<iostream>// rest of the file goes here
In this example, the #include preprocessor directive was used in order to call for the C++ iostream library files to be copy-pasted into the file for conversion into bytecode. This inclusion allows for use of C++'s built-in Input/Output features in code without needing to redefine them.
Once the preprocessor has completed expanding all of the directives included in the file, the compiler will then run through the preprocessed code and perform Lexical Analysis, also called Lexing or Tokenization, in which each token of the code is scanned and separated. These scanned tokens may also be evaluated to determine the type of token they are such as an identifier, keyword, separator, operator, literal, comment, etc. in order to improve post-processing of the tokens in the next step. The part that performs this is known as a Lexer, and once it has scanned the tokens it passes them to a Parser to perform Syntax Analysis, also known as Parsing.
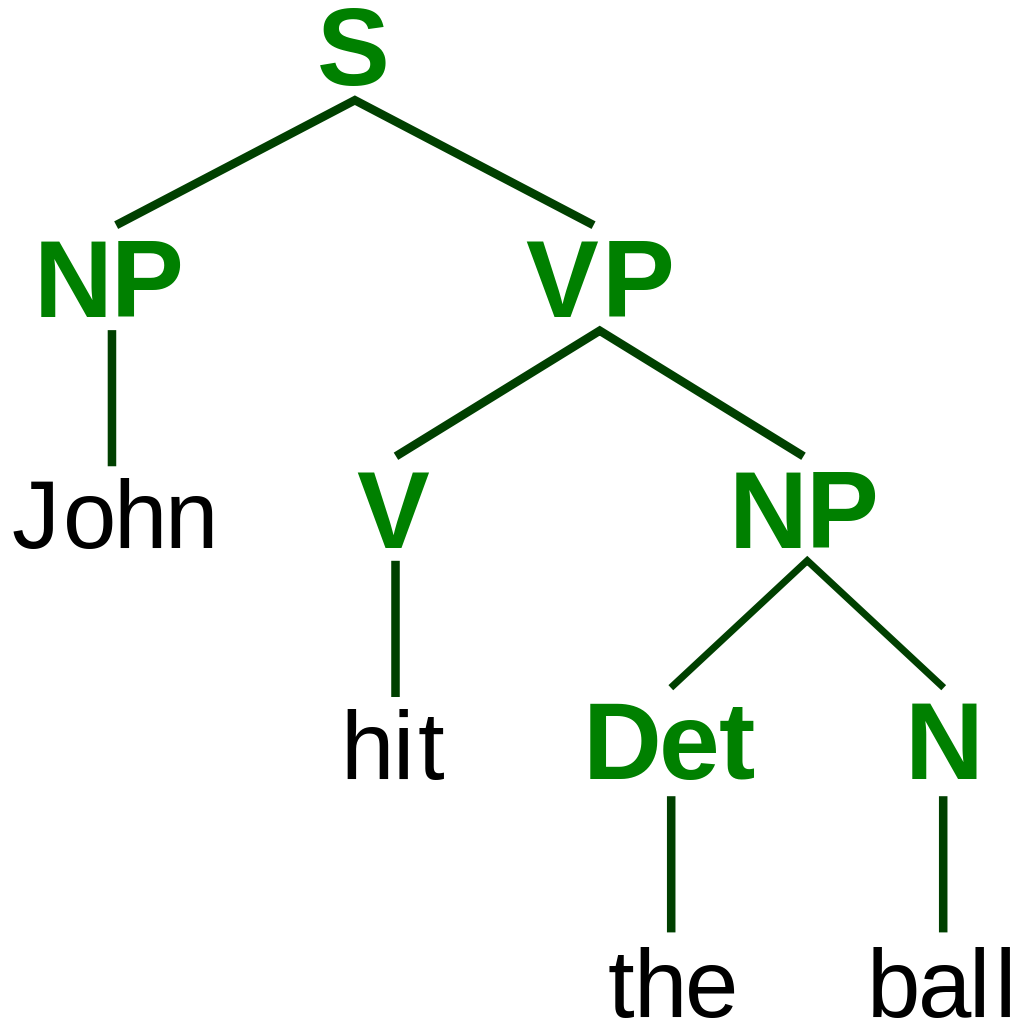
When the token sequence is parsed, the Parser will typically create a Parse Tree, which essentially breaks the tokens up into groups depending on the rules of the language. For an example of this, see this image from Wikipedia that creates a Parse Tree of the sentence "John hit the ball."
In this tree, the sentence (S) is broken into a noun (N) and verb phrase (VP). The verb phrase is then further broken into a verb (V) and a noun phrase (NP). This is then broken into a determiner (D) for particles like "the" and the noun (N) that acts as the direct object of the verb.
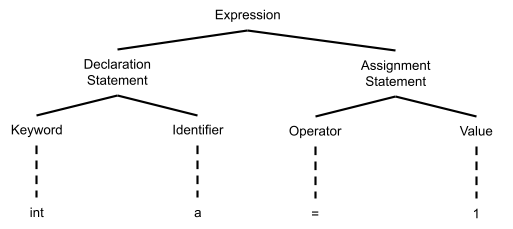
When a Parser produces this kind of tree it does so based on the rules of the programming language itself. As such, the C++ statement "int a = 1;" may be broken into the following series of tokens:
KEYWORD int (I call this a keyword because it makes sense to me)
IDENTIFIER a (an identifier is just a name of a variable kind of thing)
EQUALS (this is a defined operator, so it is just equals)
1 (literal value of 1)
SEMICOLON (Can be ignored since it holds no bearing on the code meaning)
This series of tokens may then be parsed to produce a tree that appears as such:
Keep in mind I made this myself so it is almost guaranteed not accurate, just a visualization to help understand.
Once this tree is created, the Parse Tree is then evaluated in a process known as Semantic Analysis. This is where the code is checked for Semantic Errors in order to send out errors or cancel the compilation process. More importantly, however, the Symbol Table is created, associating Identifiers, Constants, Procedures, and Functions with their defined information such as scope, type, return type, etc. For an example, take this C++ code and a Symbol Table that could possibly be created by the compiler:
intfoo(double param){
int bar = 0;
for (int i = 0; i < 10; i++) {
bar += (i * (int) param);
}
return bar;
}
(Yes, this example was plagiarized from Wikipedia, shhhhh)
Symbol Name
Type
Scope
foo
function, int
public
param
double
function parameter
bar
int
block local
i
int
for-loop statement
The symbol table will store much more information than this, including intermediate expression values, such as the one that typecasts param into an int.
Creation of this table marks the end of the Front End of compilation, and we can finally move on to the Middle End. Also, here is where lots of my beginning information is from.
The Middle End of Compilation (Optimization and Control Flow)
The most optional aspect of Compilation, the Middle End, is entirely about Optimizing the code that has been passed to it through simple analysis independent of machinery as well as developing graphs for potential control flow and the call structure of each function. Here, the compiler begins by analyzing many different aspects of the code in order to find potential ways to optimize the code. This is where the Control-Flow Graph and Call Graph are created by the compiler in order to further analyze the code for optimization. An example situation where these are helpful is in determining that a function is never called throughout the program and can thus be omitted from the final compiled file. Once the file is optimized based on coding patterns, the Middle End is finished and the Back End can begin. Here is where I got my information from.
The Back End of Compilation (Specific Optimization and Code Generation)
The final step of Compilation involves more specific optimization and the generation of a machine-code file known as an Object File. Similar to the Middle End, the compiler will analyze the code for certain criteria in order to determine ways to optimize; However, unlike the Middle End, the optimization done in this step is done in order to optimize the code depending on hardware specifications. An example of this is peephole optimization, wherein short sequences of instructions are rewritten for hardware efficiency. Following these optimizations, the code is finally translated into machine-readable code in a process known as Code Generation. As stated earlier, the file produced from this is known as an Object File and typically ends in .obj, .o, or something else depending on the compiler. Once again, here is where my information is from.
Programming Paradigms
Why Understanding Multiple Paradigms is Important
When programming, it is most important to not learn a language per se, but rather build a toolkit of concepts that can be used later. Many of these foundational ideas will have crossover between languages regardless of paradigm. This rings true especially for general-purpose, multi-paradigm languages: For example, big ones like Python, C#, and C++ are all multi-paradigm. Even Java (after Java 8) has implemented Functional programming ideas despite being considered an annoyingly Object Oriented language. Knowing the abilities and concepts of multiple paradigms is essentially a necessary aspect of being a good programmer. Overall, learning these concepts now is important to allow for a better understanding of just how professional coding should be on different projects: a deliberate choice of paradigms depending on the specific problem at hand. As such, please take the time to learn about these concepts at least in some depth just to understand the options you have as a programmer.
Introduction
In programming, there are considered to be 4 different paradigms (a language's approach to the way code is written) that are used when coding. Before reading, remember that many languages have overlap in the way that they implement paradigms, as stated before in the precursor. Building on this, I would also like to state that some paradigms are just extensions of others and are more a superset, so those are included by default. With that said, I will begin at the very baseline with the terminology used to describe different paradigms: the concepts of imperative versus declarative code.
If you want just a quick overview of paradigm differences, click here to see a chart detailing such. I recommend looking at that first and then reading my stuff if needed.
A Precursor About Imperative vs Declarative
This should serve as a short and easy descriptor to both Imperative and Declarative Programming ideologies, but I do still recommend reading the more in-depth versions as they give information about more specific aspects on top of this general description. Ultimately, Imperative Programming is defined as telling a computer every step of the process to execute in very specific terms. On the other hand, Declarative Programming is defined as telling a computer what we want to have happen in order to make the computer do things we want without necessarily defining each step. However, there is a large caveat to Declarative Programming in that it is actually all just an abstraction of Imperative Programming. For example, looking for keys Imperatively would be written as "look under the mattress, then on the couch, then in the bed, then …" whereas looking for keys Declaratively would just be "look for keys." Either way the same steps may be done, but Declarative programming separates the defined execution from the desired logic. As such, Declarative programs are just Imperative code hidden behind a language itself, as there is no other way to do so. This video is great to watch to understand
Imperative Programming and Structured Programming
As said above, Imperative Programming is the act of defining every step for the computer to execute in a sequential order. In Imperative Programming, the order of execution matters heavily as there is a large reliance on data state and expressions, which are known as statements in Imperative Programming as they modify data's state in some way. As an example, Pure Assembly Language, which is very low-level programming that depends on the computer architecture's available instruction set, is a great example of Imperative Programming, as every single step that the computer executes is defined clearly. Essentially, code would be written in one big chunk of statements that mutate the state of the program's data in order to achieve the desired result.
A purely Imperative Programming language is extremely bare-bones and really is just simply a "do this, then this, then this, and so on" form of writing code. As such, there was a large possibility for improving the quality of life aspects of Imperative languages. Given this idea, Imperative Programming was later extended by the concepts of Structured Programming, which sought to improve the flow of purely Imperative languages. Structured Programming is essentially exactly the same as Imperative Programming, but adds various ideas such as if/then/else statements, code blocking, and subroutines (functions). I include Structured Programming here because it is essentially just pure Imperative code but with some quality of life changes. This is the essence of languages with different paradigms: all are extensions of Imperative code in some form or another.
Declarative Programming
I would like to start by building on the common definition of Declarative programming given previously: Declarative programming is telling a computer what we want to have happen rather than how to do it. I stated previously that Declarative Programming is just an abstraction of Imperative programming, and so the computer in this situation is actually the language itself which has some built-in implementation of some actions. Take, for example, the following code written in C#:
Imperative
int count = 0;
int[] vals = {1, 2, 3, 4, 5};
for (int i = 0; i < 5; i++) {
if (vals[i] <= 3) {
count++;
}
}
int[] underFourDoubled = newint[count];
int cursor = 0;
for (int j = 0; j < 5; j++) {
if (vals[j] <= 3) {
underFourDoubled[cursor] = vals[j] * 2;
cursor++;
}
}
In this code, we begin with vals equaling {1, 2, 3, 4, 5}, but then take every value that is less than 4 and double it, only adding those values to a new array that we then set vals equal to. In the imperative method, I have to parse to find the number of values less than 4, create a new array of that size, then parse them again to add their doubled values to the new array. Contrastingly, the Declarative approach uses the data querying methods included in C#'s LINQ framework, specifically Where() and Select() .
Where() filters the passed in input stream that can be iterated through and adds the values to a new list dependent on if they get returned by the passed lambda expression. Select() takes an iterable input stream and applies the passed lambda expression to that data, returning a list of those changed values. These methods are built in to C# to make data-querying easier to write as they are often-done procedures. There isn't necessarily anything special about how these methods are done, they are all written imperatively, but coding using functions that hide the implementation is what makes it declarative code.
In terms of benefit to programming it this way: the main benefit of writing Declarative code whenever possible is that it allows for faster programming, debugging, and is more safe to program as the way the computer interacts with the queried function is consistent. There is also a potential for having some efficiency benefits in the form of parallel processing, but the majority of cases will be slightly more inefficient, which is really not a problem unless having very efficient code is super necessary, like when the code is being repeated over and over and over in a very short span of time.
You may have recognized by now that Declarative programming is pretty much only applicable when functions have already been defined and, due to this, not all code can be written Declaratively when only using libraries, frameworks, or language features written by others. However, as Declarative programming is essentially just done by using a clearly-defined function, or one that essentially self-comments, Declarative code can be done by abstracting a certain type of function. The functions that define a Declarative function differ from typical Imperative coding functions in the way that they must be Referentially Transparent.
Referential Transparency and Pure Functions
Referential Transparency (RT), which isn't necessary when creating functions in Imperative programming, is the defining feature that allows Declarative programs to be able to exist. In essence, Referential Transparency is the term used to describe expressions which logically allow for the expected value to be substituted in the place of the expression itself. In other words, putting an input into the function would be effectively the same as just writing the output. So, for example, passing 5 to a referentially transparent function that returns 2 * n, where n is the passed number, would be the same as just writing 10.
When applying this concept to functions rather than the more general expression, there is the concept of Pure Functions. A function is considered pure if it returns the exact same value given the same parameter values and does not alter any values outside of the function. In other words, a function is pure if it has no dependencies on variables that aren't passed in as parameters or defined in the function and cannot alter any value that is defined outside of the function, even the parameters. The idea of changing no variables outside of the function is known as a function having no side-effects. For an example, look at the following Pure function and Impure function (Written with Java syntax):
Pure
intpure(int x, int y){
int val = x + y;
val = val * 2;
return val;
}
This function is considered pure as the only values that it alters are defined within the function itself, and the returned value only depends on the value of the parameters x and y, no other outside variable alters the returned value.
Impure
int globalVal = 3;
intimpure(int x, int y){
int val = x + y;
val = val * globalVal;
globalVal += 1;
return val;
}
This function is considered impure for two reasons. The first reason is that it is dependent on the external variable globalVal. Due to this, the function will return a different value, even when given the same parameters, if globalVal is ever changed. Secondly, the function modifies the value of the external variable globalVal. This is a side-effect.
Pure functions must return the same value given the same parameters and have no side-effects. There can be no dependence on or changing of external variables.
As stated previously, a Referentially Transparent expression must be logically substitutable with the value that would be returned. In this way, Pure Functions, which return the same value given the same parameter and have no side-effects anywhere else in the code, are required for Referential Transparency. Essentially, an expression is Referentially Transparent if it itself is Pure and every function it calls is Pure as well. This is the defining feature of a Declarative language, the fact that it does not allow for functions to mutate any external values and is consistent in its expressions' returned value. The idea of having all pure functions and not mutating any values of the class itself is known as being stateless and is an important aspect of many languages that build on the Declarative ideology.
As writing referentially transparent expressions are the main requirement of Declarative programming, it is actually possible to write Declaratively even if there are no libraries, frameworks, or language features available for the task you need to complete: you can just write your own referentially transparent functions with, ideally, self-commenting identifiers (self-commenting means that it is essentially clear what is done by the function just by the name itself, take Where() for instance).
Also, as just some extra jargon for you, the reason why Declarative programming is considered good is because of the way that there is often code written for common actions in coding. These functions and languages are known as Domain-Specific. Take, for example, the field of creating user interfaces. Oftentimes there will need to be a way to create a button that updates something on being pressed. This is needed so often that entire frameworks and libraries are made just for that domain, for example: Angular, React.js, or Solid.js. Each of these are Domain-Specific, Declarative additions to JavaScript that allow for a much easier, more consistent way to create user interfaces (once learned, of course). They each abstract the creation of user interfaces so a button doesn't need to be implemented by the programmer that uses it.
Logical Programming
Logical programming is a subset of the Declarative Programming ideology and involves defining a set of rules and facts, allowing the computer to then decide on its own how to interpret those rules when a question, called a query, is posed to the computer. The computer does this based on the concepts of formal logic, which is a complex field in itself, so I will not explain that here. For an example of how a logical program would look, here is some abstract code written in ProLog, a logic programming language:
// sandwich is a food (Fact)
// sandwich is a lunch (Fact)
// Any food is a meal/Anything is a meal if it is food (Rule)
// What is both a meal and lunch (query)
In this instance, the computer would look at the query, determine what rules and facts it would need to look at, then return an answer. For this program, the computer would return "Answer : X = sandwich."
If you want to learn more, here is the Wikipedia article on logical programming. As said before, logic programming works based on the rules of formal logic and is defined by those ideas.
Procedural Programming
Procedural programming, similar to Structured programming, adds more ideas to the concepts of the Imperative Programming ideology by extending Structured Programming even more. As it is still Imperative Programming, Procedural Programming involves directly telling a computer step-by-step what to do, but Procedural Programming modularizes Imperative Programming through the use procedures (functions/routines/subroutines). Procedural Programming added the concepts of modularization (separating functions into different, interactable modules), local variables, iteration and other things to Structured Programming. Ultimately, there really isn't much logical difference between Procedural, Structured, and Imperative programming, but they still have different capabilities technically.
Object-Oriented Programming
Object-Oriented programming is a further extension of the Imperative Programming ideology and adds even more onto the ideas of the Procedural Programming paradigm, and is one of the easiest paradigms to understand as it is one of the most analogous to real-world concepts. In Object-Oriented programming, concepts are represented as classes (objects) that can have data, alter data, both, or neither. Object-Oriented Programming added many concepts associated with Objects, such as data abstraction, inheritance, polymorphism, and much more. This paradigm is liked due to its allowance for easy code-sharing and understandability. Polymorphism is the main defining feature of Object-Oriented Programming and can allow for Data Abstraction through interfaces and inheritance and is ultimately what makes this paradigm powerful. Encapsulation is also important, but can very easily be done wrong by creating too many unnecessary classes to just do one thing, so be careful when using it on smaller scale projects. It is the strict dedication to encapsulation that makes this paradigm hated by so many despite the incredible benefits that can be gained from smartly using polymorphism and inheritance.
Functional Programming
Functional programming, like Logical Programming, is also a subset of the Declarative Programming ideology, and is effectively just a close representation of that ideology. Ultimately, functional programming doesn't necessarily depend on the representation of objects, but rather as a representation of repeatable actions to be done given certain data. In a functional programming language, functions are considered to be first-class citizens, meaning that they are able to be used like any other data entity. A first-class citizen function can be stored in a variable, named, returned from other functions, and passed to other functions. The main descriptor of this language comes in the way that purely functional languages will often restrict the programmer from mutating the state of the program, forcing the program to be Referentially Transparent throughout. This allows for the first-class citizen status of functions, making Functional programs essentially doing actions based on, or with, actions. There are many benefits to using functional programming, if it is supported, as it can eliminate a lot of the boilerplate code (code that is repeated with little or no change) that occurs often in Object-Oriented programming. See the declarative topic for an example of functional programming since my example is pretty much Functional.
The Benefit of Stateless (Pure) Functions
As Functional-Programming functions are defined as stateless (Pure), the order of execution of functions doesn't always matter, which allows for parallel processing to be done in order to more efficiently complete a problem on a PC with multiple CPU cores, which is pretty much all of them nowadays. This one factor is what leads stateless code to be more efficient in general in terms of runtime. While it may be unintuitive, ultimately a program that can use multiple cores at once is faster than one that is more efficient but can only use one core.
The downside to this is that the order of output can vary and will likely not be the same as the order of input, so don't use parallel processing if order of data matters a lot.
An example of this can be seen here, the parallel processed version of LINQ queries, which I had touched on here.
Lambda Expressions (Anonymous Functions)
A Lambda expression in C# is identifiable by the => arrow operator that defines the expression. A Lambda Expression is effectively a non-Functional language's approach to adding in some form of Functional Programming concepts. A function that is defined using a lambda function is known as an Anonymous Function. It is called such due to the fact that it is nameless (it has no definable function signature to call it with). Creating an Anonymous Function (Lambda Expression) is important as it allows for the languages that support it to create functions like variables. That is to say, an Anonymous Function is capable of being applied to a variable and passed to other functions as well as called through that variable. C# actually takes this concept further through the language's take on function pointers in the form of Delegates. This is important for methods that require being passed some form of Delegate-typed variable in order to function, like LINQ's Select(<selector>) method (used as an example here). LINQ is just a part of C# that makes iterating through things easier and is just quality of life basically. A Lambda expression can be written in C# in the two following forms:
The Expression Lambda, which just uses a single expression as the body that it executes. This is written in the format:
return-type (input-parameters) => expression
The Statement Lambda, which uses a sequence of statements as its body that it executes. This is written in the format:
Keep in mind that these can be split into multiple lines for readability and that Statement Lambdas typically contain no more than two or three statements in the body.
As such, here is an example of defining a Statement Lambda as well as applying it to a variable of type var, which creates an implicitly-typed variable (one whose type is decided by the compiler), and calling it. (All with C# syntax)
var LambdaFunction = int (int x) => {
string number = x;
Console.WriteLine(number);
return x + 1;
}
int incrementedX = LambdaFunction(562);
This statement creates a var named LambdaFunction, defines the lambda expression and applies it to LambdaFunction, then creates a new int variable incrementedX, which then gets applied the result from LambdaFunction(562).
Additionally, oftentimes it is unnecessary to define the return type before the input parameters as the compiler can interpret it on its own. The compiler can often also infer the type of the input parameters and so those may also occasionally be left out. Along with those, when defining a Lambda using the Expression Lambda format, the result of the single expression is automatically returned even without specifying with the keyword. As such, in contrast with my previous example, here is an example of an Expression Lambda that has the compiler infer as much as possible, with the Lambda being applied to a var variable and called in order to apply the result to an int variable.
var ExpressionLambda = x => x * x;
int squaredX = ExpressionLambda(2);
In this example, the return type, type of the parameter x, and type of ExpressionLambda are all decided by the compiler. On top of this, since we used an Expression Lambda, the return keyword could also be left out.
There are many more aspects of Lambda Expressions/Anonymous Functions that I left out from here as I did not want to get into specific use cases or anything of that sort. The main takeaway here is the fact that Lambda's are essentially the way to use functions as they exist in Functional Programming languages within Object-Oriented Languages, which can help efficiency, improve readability, and cut down on boilerplate code.
For more on Lambda expressions and how to format them and their inputs, view the API by clicking here.
Inline Functions
Understanding inline functions are important for understanding the function of Anonymous Functions and the Delegate typing. In essence, an inline function is the programmer making a function which the compiler has the ability to potentially copy-paste the function's code in the area where it is called in order to improve the efficiency of the program when the function is called a large amount of times and is relatively small. This explanation on its own is confusing, so take this somewhat extreme example:
inlineintaplusb_pow2(int a, int b){
return (a + b) * (a + b);
}
for(int a = 0; a < 900000; ++a)
for(int b = 0; b < 900000; ++b)
aplusb_pow2(a, b);
Since the aplusb_pow2(int a, int b) function would end up being called around 810,000,000,000 times in this loop, the amount of time that it would take to continuously make a function call would be much higher than if the function's code was simply placed there. As such, when making a function inline, the compiler would decide to potentially replace the "aplusb_pow2(a, b)" in the for loop with "(a + b)*(a + b);", which saves a large amount of processing in a situation like this. This process of pasting the body of the function in the location where the function is called is known as inline expansion, and you can read more about it here. For a better example of how an inline function works, consider the following wherein the inline function swap(int a, int b) gets compiled:
First, the function gets defined as inline:Definition of the Inline Function
inlinevoidswap(int a, int b){
int temp = a;
a = b;
b = temp;
}
Then, the programmer calls the function:What the Programmer Writes
swap(x, y);
The compiler then makes the decision to instead copy and paste the body of the method in order to save from doing a function call, so the code effectively would look like this:After Inlining
int temp = x;
x = y;
y = temp;
Check out the wikipedia article on inline functions if you want by clicking here.
Pointers
There are many times when a pointer might be useful for saving time, but understanding them requires a bit of knowledge about computer architecture. Pointers are extremely important in C and C++, but, for higher level languages like C# or Java, they are mostly handled by the compiler. For more on C# pointers, click here. On that linked API, scroll down to about a third of the way down if you want to see all the operations can be done on pointers.
A pointer in coding is simply a reference to a location in memory. This is the most primitive form of a reference, and can be made in C# through declaring a variable of a certain type with an asterisk at the end of the variable's type declaration. This can then be assigned a memory address to point to by using the unary operator "&". For example, here an int variable and a char variable as well as pointers to their types are made. These are assigned the memory locations of the actual data in order to point to their locations:
In this example, let's say the memory location of exampleChar is 2036. Using the ampersand operator as shown above in "&exampleChar" returns the number 2036. This then gets stored in the pointer (declared by using the asterisk operator).
A pointer is typically considered unsafe code as it is incapable of being determined as verifiably safe code by the compiler. Typically, safe code doesn't use pointers or mess with the memory directly, and, as such, the use of pointers may be considered unsafe code, which can result in security issues or crashes.
Pointers to pointers can be also made through setting the referent type, (which is the type of data that the pointer points to), to a pointer type. For example:
int** pointerPtr = &ptr;
this creates a pointer that refers to a pointer with a referent type of int. An array of pointers of a certain referent type can also be made through the use of brackets. For example: "int*[]" would create an array of pointers with a referent type of int.
The pointer indirection character (the asterisk) can also be used to access the data in the memory location that the pointer points to. Taking the data from the first example with the exampleChar variable, having the code:
Console.WriteLine(*charPtr);
Would write the character "a" into the console, as that is what was stored in the memory location that the pointer referenced. The action of accessing the value stored at the memory location pointed to is known as "dereferencing".